Why Voice AI Agents Struggle in Indian Education: A Deep-Dive into the Challenges

Engineering Team
Skilld Enroll
"The Great Voice AI Disconnect: Why Technology Promises Fall Silent in Indian Universities"
Voice-enabled chatbots promise to democratize information and personalize support across India’s vast, multilingual education system—but real-world deployments quickly hit serious roadblocks.
This blog unpacks the technical, infrastructural, socio-cultural, and regulatory hurdles that keep voice agents from reaching their full potential in Indian universities and schools.
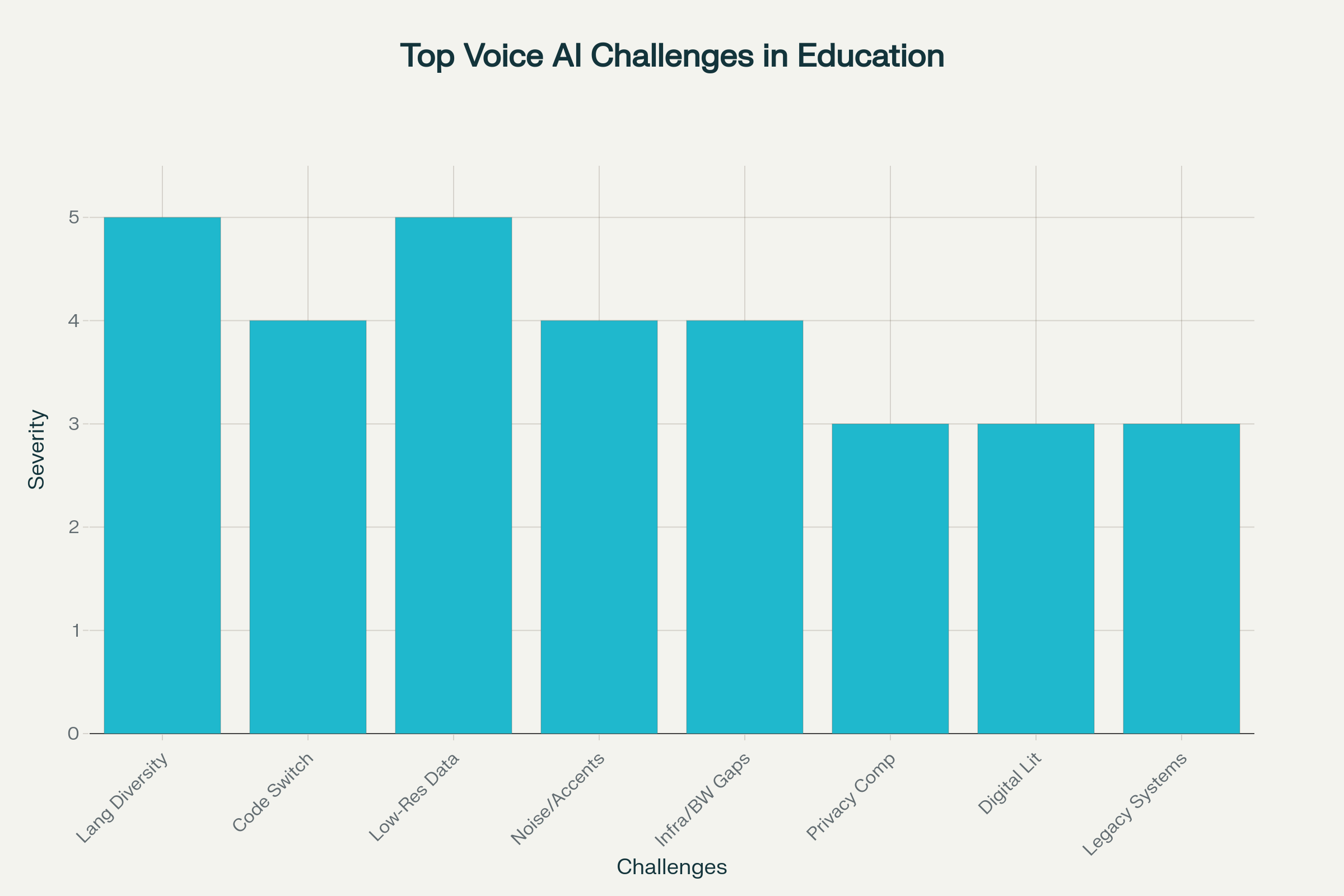
Top Technical and Contextual Challenges Hindering Voice AI Adoption in Indian Education
1. Linguistic Diversity: One Country, 19,500 Mother Tongues
India officially recognizes 22 scheduled languages and over 19,500 dialects. Each language family—Indo-Aryan, Dravidian, Tibeto-Burman—has unique phonetics and script conventions. Even within Hindi, pronunciation varies sharply between Jaipur and Lucknow, confusing generic ASR models.
Phoneme Overlap: Consonant clusters common in Hindi (e.g., “ज्ञ”) or retroflex sounds in Tamil are absent in English-centric models.
Script Fragmentation: Training datasets must map Devanagari, Bengali, or Malayalam scripts to a single acoustic model—a non-trivial engineering feat.
Dialects vs. Datasets: Only a handful of Indian languages enjoy large transcribed corpora; many tribal or regional tongues remain “low-resource,” starving ASR engines of training material.
2. Code-Switching & “Hinglish” Chaos
Indian students routinely mix English with regional languages (“Kal viva hai, can you reschedule?”). Code-switching ruins conventional single-language decoders and inflates Word Error Rates by 30-50%. New tokenizer and prompt-tuning tricks for Whisper help, but they add latency and still lag in accuracy for spontaneous mixing.
3. Data Scarcity for Low-Resource Languages
Building robust voice models demands thousands of hours of labeled audio. Hindi and Tamil datasets exist, but languages like Bhojpuri or Khasi have minimal digital footprints. Continual-learning research tries to add languages sequentially, yet suffers from catastrophic forgetting when new tongues are introduced.
4. India’s Acoustic Reality: Noise, Accents, and Cheap Mics
Campus corridors, autorickshaw horns, and crowded hostels create background noise far above ideal lab conditions. Low-cost smartphone mics introduce distortion, further degrading ASR performance. Studies show WER jumping 15-20% when ambient noise exceeds 12 dB, common in Indian cities.
5. Connectivity & Infrastructure Gaps
Reliable 4G or broadband is still patchy: only 37% of rural households have stable internet. Universities complain of bandwidth congestion that throttles real-time streaming models. Without edge processing or offline fallback, voice agents time-out precisely when students need them.
6. Privacy, Compliance, and the DPDP Act
The Digital Personal Data Protection Act 2023 introduces stringent consent and localization rules. Voice agents record biometric data (voice prints) that must stay on Indian servers and be deletable on demand. Red-team audits reveal spoofing and data exfiltration risks that can trigger multi-crore penalties.
7. Digital Literacy & Cultural Acceptance
Faculty often distrust “robot counselors,” fearing job displacement or data misuse. Students in rural colleges may hesitate to speak English phrases or upload voice notes, reducing engagement. Training programs and bilingual UX design are mandatory but rarely budgeted.
8. Integration with Legacy Campus Systems
Most Indian universities still run siloed ERP or spreadsheet workflows. Voice bots need real-time hooks into admission, exam, and finance modules—yet APIs are undocumented or absent. Custom connectors balloon project timelines and costs.
9. Cost–Benefit Math vs. Accuracy Ceiling
Universities demand sub-10% WER for mission-critical queries (fees, scholarships). State-of-the-art Hindi ASR on noisy data still hovers at 14–18% WER. When accuracy falls below expectations, administrators abandon pilots, calling the ROI “unproven.”
10. Path Forward: Pragmatic Fixes
Language-First Engineering: Use phonetic scripts (LIPS) and family-based prompt-tuning to lower WER in low-resource tongues.
Edge & Hybrid Models: Deploy on-device ASR for FAQs; reserve cloud GPUs for complex dialogs—cuts latency under poor bandwidth.
Noise-Robust Training: Include real campus recordings with honks, fans, and chatter during model finetuning.
Privacy-by-Design: Encrypt voice streams end-to-end; auto-purge raw audio after transcription; comply with DPDP audit trails.
Faculty Co-creation: Involve teachers in intent design to build trust and ensure culturally correct responses.
Open Datasets & Grants: Government-funded MUCS challenges supply 600 h of labeled audio across seven languages—still a drop in the ocean, but a start.
Bottom Line
Voice AI can transform admissions hotlines and learner support across India—but only if builders confront linguistic complexity, infrastructural gaps, and strict privacy norms head-on. Early adopters who invest in noise-robust, multilingual, compliant voice stacks will own the next wave of inclusive EdTech.